This is not so much of a SRE post, be ye warned, but it does discuss solving problems creatively. WARNING: Blindly following this will result in incurring costs from cloud providers, potentially quite a bit. It’s not my fault if you don’t calculate how much your task will cost. As an example, had I used AWS Comprehend for my sentiment analysis, I calculated the cost at ~$15,000.
Why on earth would you need to know the gender of Github users, you ask? If you’re conducting research on bias in pull request acceptance rates, that’s why. I’ll leave the background and meta-analysis of existing literature for, you know, the actual report. The tl;dr is that research suggests that women’s pull requests are declined at a higher rate than men’s if they are identifiable as a woman in their avatar, despite statistically creating objectively better code. The tl;dr of my findings is that I failed to reject the null hypothesis, with the heavy caveats of me using a small subset of data, having only a single semester of experience with machine learning, and only training the model on a subset of my subset of data. YMMV, and I in no way want to express finality on my findings. The report and all scripts are here. You should follow along in the report, Chapter 3, if you want detailed instructions on how this all works together.
GHTorrent is an amazing project that has ~6.5 billion rows of information from Github. It’s also quite a bit larger than my server cared to deal with (stay tuned: Goldspinner v2 is coming), although I did try. Google BigQuery to the rescue, since the project already exists as a publicly queryable resource.
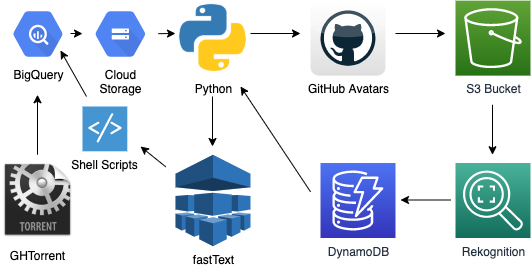
Why the cross-platform? As mentioned, the data exists in BQ already (to be fair, I actually didn’t check Redshift), but Rekognition is 66% (ignoring free tiers) the cost of Vision. Also, uh, Vision doesn’t report gender. Google’s reasoning isn’t inherently bad, IMO - in fact they make a good argument against government agencies abusing it to misgender people - but for the purposes of this project, I need to be able to return predicted gender. This may introduce some wrinkles with trans people, but it’s my hope that if the person has made strides towards living as their affirmed gender, their avatar will reflect that such that Rekognition correctly identifies them. I am open to discussion on how this could have been done better.
Before settling onto image recognition, I was taking lists of “known names,” i.e. traditionally gendered names. I then passed each name through a small function using fuzzy-pandas and Levenshtein distances for rough matching. This worked-ish for people with actual names as their username, but was tremendously slow, and of course had far less accuracy than checking profile pictures. It’s included in the repo for posterity. The threshold was empirically determined. I do not recommend this method unless you are utterly strapped for cash, in which case please ensure that you dedupe the input list first.
My first useful queries on BQ resulted in massive tables, around 14 TB. This would result in a storage cost of $9.33/day, and a query cost of $20. This isn’t reasonable for my purposes, so I had to pare them down. Ultimately, I opted for the latest year of data (2019), and analyzing a single day per month. I went with non-holiday Mondays, since Mondays have the highest number of commits. By evaluating multiple months across seasons, I hope to eliminate natural variations.
You’ll first want to cut down the existing tables into more manageable pieces. Specifically, you need comments, project_commits, and pull_request_comments. You can find a usable query in my repo.
Next, run the query, substituting whatever date range you’d like. One day should give you somewhere around 16 - 20 GB.
Export the table to GCS - create a bucket if you need to. Next, get them onto your computer by some means. I used gsutil sync. Be aware of data export costs. You can, of course, use a Compute instance instead, but you’ll need to get stuff into AWS somehow for Rekognition.
Next, Python. I’m using Jupyter Notebook, but you’re welcome to do it in hard mode if you hate yourself. You’ll need to get PIL, boto3, and pandas with pip first. Also of note, the astute among you may note that this in no way scales. In fact, it’s dead-awful for anything over a few hundred or perhaps thousands of images. I did create a pipeline using SQS (also briefly RabbitMQ) and Lambda. It did work, but I got the concurrency and/or timeout settings wrong, so while the Lambdas happily drained the queue of ~42,000 images in seconds, only ~70 of them made it through Rekognition. Rather than waiting to push everything into the queue again, I just left the Python script running overnight doing sequential calls. To avoid unnecessary cost expenditures, you can first do some pruning before running avatars through Rekognition. Empirically, I determined that 12 KB was the cutoff for default and/or cartoon avatars. I cut out about 6,000 files by doing this. You could also search for duplicates if desired.
You’ll need to also load these files into S3 before you can run the script. You can do so via the console, with aws s3 sync, or from within Python. Just get them in there somehow. You’ll also need to set up an IAM user for Rekognition, and give the bucket a reasonable access policy. I think GetObject is all it needs, but double-check AWS docs. Don’t do Public Access. Just don’t.
Rekognition will dump its findings into a DynamoDB table (I’m sure there are other ways, but this is easy, and slots easily into the free tier for the short period of time it’s needed), from which you can export it as JSON. Use jq to parse out anything under n% confidence, whatever you’re comfortable with - I went with 99%, which gave me ~17,000 images. If you’re reading along in the report, you may have spotted an error with respect to producers/consumers - what fun!
You can then find the intersection of comment authors with the returned filenames, and then run those comments through whatever sentiment analysis you’ve chosen. I used fastText, in supervised mode. First you have to manually label data, or you can try to adapt one that exists already. I didn’t have very good luck with existing models, as they’re mostly trained on normal human speech and comments, not PR comments. As you are probably aware, the line between objective criticism and unnecessary harshness in a PR comment is razor-thin. I didn’t start seeing reasonable accuracy until ~300 comments had been tagged, which really takes a short amount of time with the script I wrote. Accuracy continued to improve up until ~1300 comments, at which point it began regressing. I assume I erroneously tagged something beyond that, and the model latched onto it. Effort could be made to strip comments by bots to further improve accuracy.
The actual training I performed on a 96-vCPU EC2 instance for the purposes of speed. fastText is multithreaded in training mode, so you can get a huge amount of training done in a very short amount of time with high core counts. You can certainly also run this on your local machine, though.
Once you have your model, you run all desired comments through it, and generate a CSV with columns you can join on in the original BQ tables. Alternately you could do this all within Python, I suppose, but the memory necessary to do so would be quite a bit, unless you write a clever chunking algorithm. BQ is faster and easier.
How much does this all cost? For AWS, running ~42,000 images through Rekognition cost me about $37, EC2 was also about $37 between the instance and its EBS (it was idle for about a month, so EBS adds up), S3 was about $1, and data transfer costs were about $16. For GCP, exports from GCS were about $25, BQ queries were about $8, and BQ storage was about $7. Total cost, $131 plus tax. You can probably keep this in free tiers if you limit the time, run as much as possible locally, and use small BQ queries and Rekognition calls - for BQ, I used 2.7 TiB of BQ storage and 358 GiB-mo of BQ storage; free tier is 1 TiB and 10 GiB-mo, respectively. Rekognition allows for 5,000 images for free.
The SRE portion of this could be seen as the pipeline creation, and automating some of the joins. Cloud architecture is something that interests me, so I’m trying to improve my knowledge on how best to join systems together to get the desired result.