This is not a blog entry on how to move Lightsail content to EC2, as those guides already exist in AWS’ fantastic documentation. This is about my trials and tribulations in getting it up and running, and how I fixed a niggling problem I’ve had since the beginning of this blog (and the other sites running alongside it).
Past readers will note that that I’ve had issues with this site running alongside its siblings. After being led astray by visions of hackers (script kiddies, anyway) and MariaDB tuning minutiae, I believe the problem was simply a lack of memory. The Lightsail instance this was running on, the smallest available, is roughly equivalent to a t2.nano - 1 vCPU, 512 MiB RAM. That proved inadequate for four simultaneous WordPress instances in Docker, leading everything grinding to a screeching halt ~1x/3-4 weeks, with the only cure being a full instance halt and start.
After discovering that Reserved Instances are remarkably cheaper than On-Demand (who knew?), I calculated that a 1 year contract for a t3a.micro (AMD Epyc instead of Intel Xeon - I heart AMD anyway, so the cost savings was a bonus) was nearly the same as I was paying for the Lightsail instance. Had I wanted to swear fealty for three years, I would save even more, but let’s see how this goes first, shall we?
Got the RI purchased, figured out how that you don’t actually have to link it to any instances, it just figures it out, and had everything up and running in no time. Just kidding, it took me multiple attempts just to get any page to resolve, even when I spun up an nginx hello-world example, because I forgot to open 80/443 traffic. D’oh. After that, my next task was to tackle one that had been haunting me since the creation of the site cluster: www.
You may know (if you don’t, congratulations) that URLs need not contain www as the prefix. This website resolves fine with https://sgarland.dev - and indeed, until today, that’s the only way it could resolve. “Why didn’t you just CNAME it, you dummy,” you may rightfully ask. Well, I did, and it didn’t fix it. The issue is that the site is being run behind an nginx reverse proxy, in order to have multiple sites being hosted from a single server. That proxy is set up to look for incoming host names, and redirect them to an internal Docker IP address based on that hostname. Additionally, and this is crucial, I was also using a Let’s Encrypt container to get TLS certs for the sites. Try as I may, I couldn’t get the configurations to play nicely with both the www and non-www domains. I had thought (and I’m honestly still not sure why this doesn’t work - if anyone does, please let me know) that I didn’t need to touch my server-side config, since CNAME is just a DNS record, so https://www.sgarland.dev should redirect to https://sgarland.dev before it ever saw my server. That was not the case, so I could only get one of them up at a time - less than ideal.
I, like I suspect most computer-savvy folk, don’t type www. Hell, I don’t type the domain past a letter or two most of the time, since Chrome auto-completes everything. However, for someone new to a site (remember, I’m hosting four sites, and half of them have nothing to do with technology), and especially someone less familiar with computers, they may type it out of habit. Having to emphasize to people to not include it was irritating. Something must be done.
I finally fixed it with Cloudflare. Cloudflare, among other things, will issue you a TLS cert automagically (self-signed by default, you can get a Cloudflare CA-signed one if you want) for any domain proxying through them. You then get the added bonus of their CDNs, caching, compression, DDoS protection, etc. I swear, I’m not trying to make this a sales pitch for Cloudflare, but this stuff is dead-easy to do. I disabled the portions of the docker-compose.yml that were calling the Let’s Encrypt service, modified my /srv/www/ site entries to have both the domain and www.domain as options, and enabled DNSSEC for good measure on all the domains. Boom, done, they all work.
Another MASSIVE benefit is logging and monitoring. I have previously mentioned that I work for a monitoring company, but as their EC2 connectivity relies on Cloudwatch, and AWS doesn’t integrate Lightsail with Cloudwatch, I was previously SOL. Not anymore! I’ve got a dashboard set up showing me metrics galore for instance, by which I mean T3 credit balance, CPU utilization, network throughput, free memory, and free disk space. I also discovered that AWS thinks it’s a good idea (I mean it is from a making-money standpoint) to force disk and memory stats to be custom metrics in Cloudwatch, thus incurring more charges. As I care mostly about memory, I diligently did so, and also set up custom Datasources in my LM dashboard. Finally, I set up the new metrics to alert at what I hope are acceptable levels, and opted to disable SMS notifications during sleeping hours, because honestly if these sites are down when I’m asleep, I don’t care. I mean, I care, but not enough to wake up and troubleshoot them.
So, that’s it! Doubled the vCPU, doubled the memory, with monitoring galore. Once I get some good data graphed overnight on the dashboard, I’ll update this post to show it off.
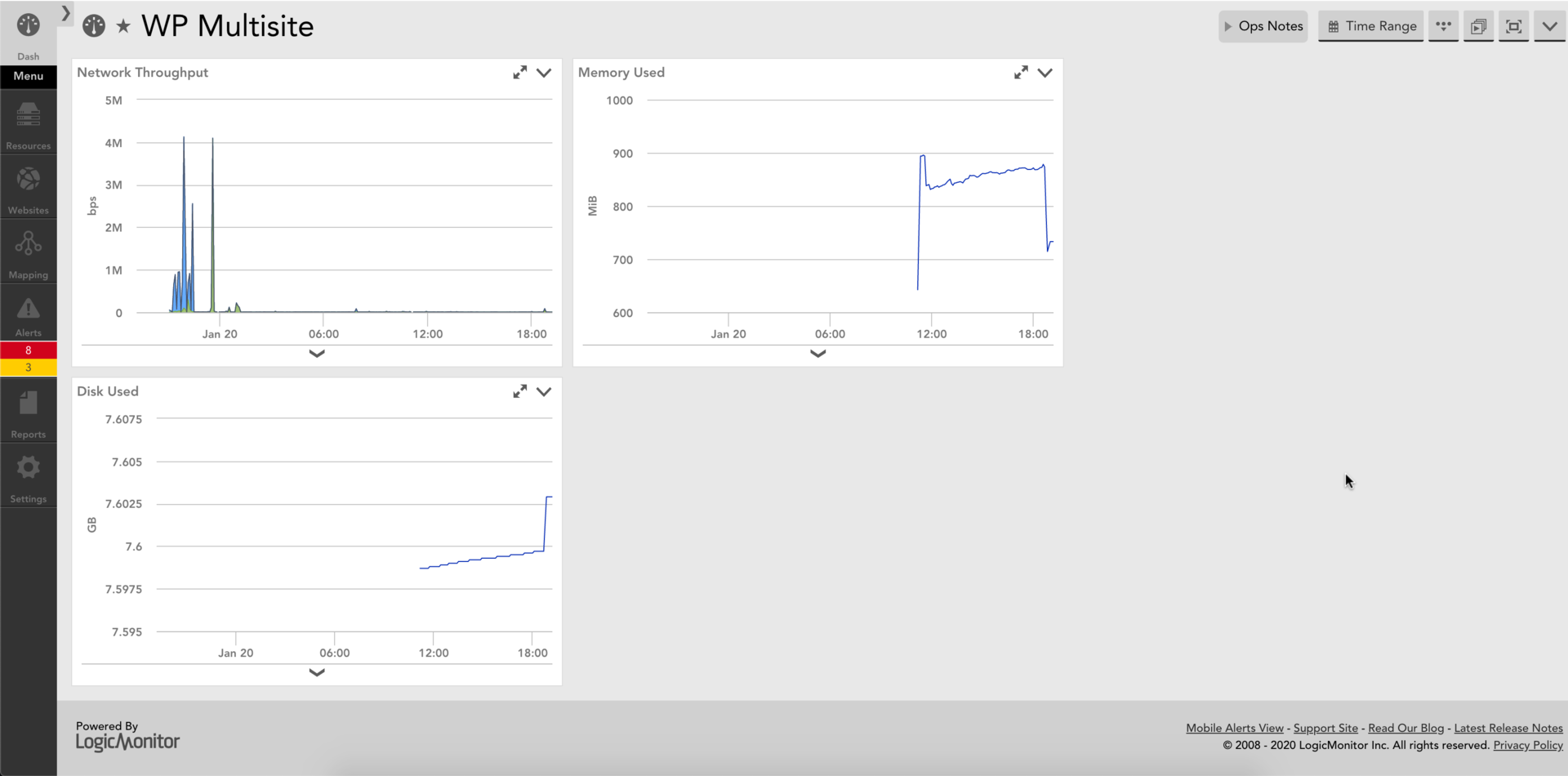
This is what I have set up - I ran some stress testing for a bit to make the CPU graphs less boring, and also to see how it served webpages with the cores being flogged. It had no issues. I’ve set up alerts for when available memory dips below 32 MiB, may need some tuning, but we’ll see how it works out.
Regarding TLS certs, it came to my attention after further research that I’ll still want to set up certbot or something similar to automate certificate renewal, in order to get one signed by Cloudflare. I’ll look more into that later - or I may be able to get the Let’s Encrypt container working again.